Quelques astuces qui facilitent l’utilisation de tables de molécules sous Microsoft Excel et ChemAxon JChem. Le module JChem permet d’intégrer des molécules en tant qu’objets éditables (ChemAxon Marvin), redimensionnables, sans déformation et vectorisés. La table peut comporter plusieurs colonnes de molécules (par exemple des sels et des molécules) sous la forme de formules développées ou de chaines SMILES. La formule trouve sa puissance dans la collecte de molécules pour différentes applications: inventaires chimiques, chimiothèques, ligandothèques … Nous partons donc d’une feuille Excel, avec deux types de colonnes: des formules chimiques et des descripteurs, notamment : textes, valeurs numériques, niveaux de couleurs, listes à choix multiples.
D’après un article publié dans buildblog.buidez.net en 2021, 2023 – Mise à jour mars 2025.
1. Coloration en fonction de la valeur de la cellule
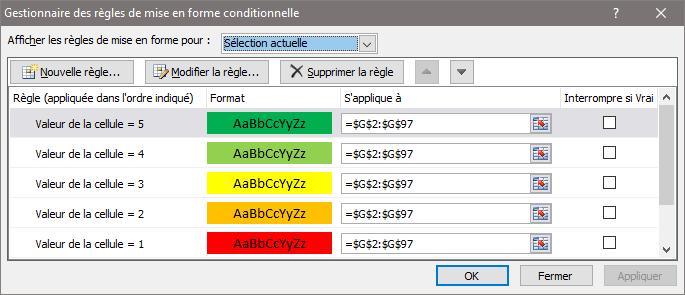
Nous allons utiliser ce que l’on appelle une mise en forme conditionnelle. Application: visualiser la quantité de molécules qui reste, sans lire des valeurs (masses en mg), mais mise en évidence avec des couleurs, selon un niveau de stock : il n’y en a plus, il y en a un peu, beaucoup … Chaque niveau est associé à une valeur (de 0 à 5 inclus, qui ne correspond pas à une masse pesée) et à une couleur. Pourquoi ne pas donner la vraie valeur du stock en mg ? Pour deux raisons: i) la quantité est rarement mise à jour par pesée après prélèvement; et ii) ce qui est important, c’est de savoir s’il en reste beaucoup ou peu (traduction: je peux en donner ou je le garde pour nous) et non une valeur précise.
Il faudra sélectionner la plage de cellules (par exemple la colonne Stock) puis onglet ‘Accueil‘ et ‘Mise en forme conditionnelle‘. Plusieurs règles sont possibles dans le menu, on peut les travailler de manière à obtenir une échelle de couleur sur n valeurs. L’exemple suivant montre une échelle de 0 à 5 (inclus) qui s’affiche avec les couleurs noir (0), rouge (1), orange (2), jaune (3), vert clair (4) et vert (5).
 |
Il est également possible de travailler sur des intervalles, plutôt que sur des valeurs. Il est également possible d’utiliser un gradient de couleur sur l’intervalle des valeurs possibles plutôt que des couleurs fixes correspondant à une valeur donnée. Pour établir des règles de manière à générer une échelle, le plus simple est d’utiliser des cellules au format numérique.
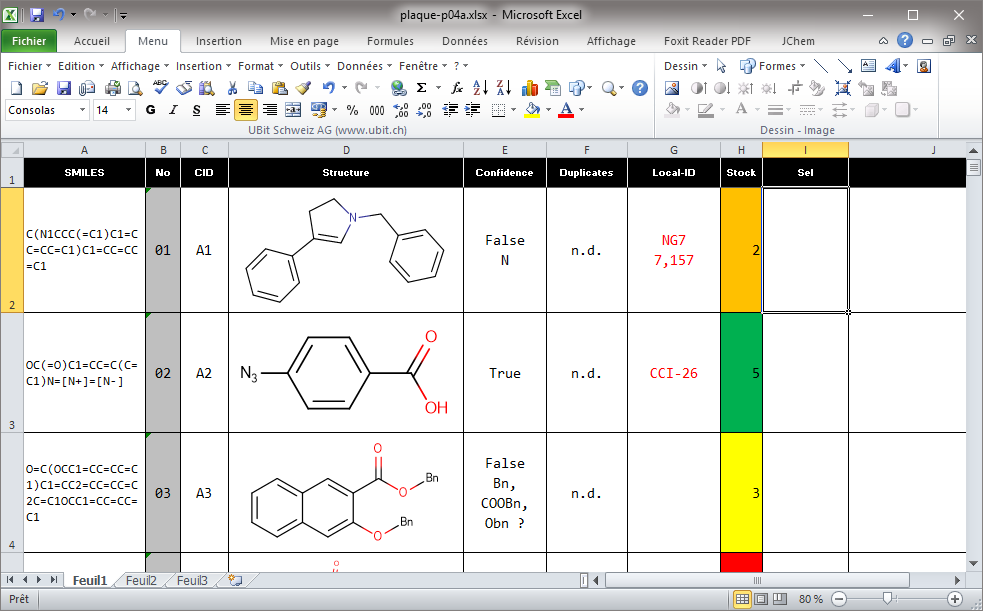
Une fois que la mise en forme est en place, chaque cellule apparait avec la couleur correspondant avec la valeur. Il ne reste plus qu’à masquer le contenu des cellules marquées.
 |
2. Masquer ou afficher des valeurs de cellule
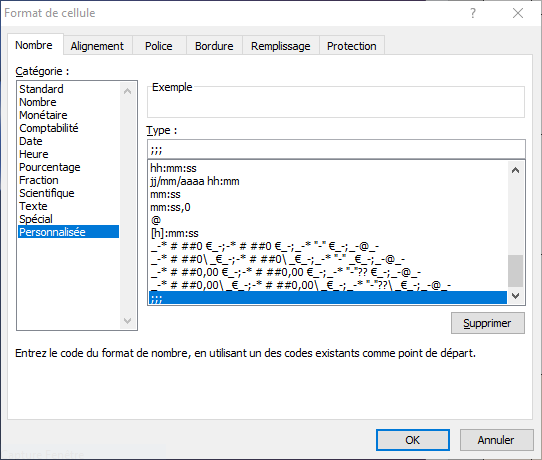
Pour masquer le contenu de cellules, il faut sélectionner la plage de cellules (par exemple la colonne Stock) puis onglet ‘Accueil‘ puis ‘Format‘ puis ‘Format de cellules‘. Aller dans la catégorie ‘Personnalisée‘ et ajouter le type ;;; (3 points virgules successifs).
 |
Le résultat apparaîtra dans la section/image suivante, les valeurs ont disparu de a colonne Stock il ne restera que la mise en forme conditionnelle (couleurs). Pour afficher le contenu, il faut revenir au format initial (Standard, Nombre, Texte …) sans oublier de rétablir la mise en forme (par exemple le nombre de décimales) qui a été remis à la valeur par défaut (2 décimales) par le masquage des valeurs de cellules.
3. Faire disparaitre la barre de formule et les titres
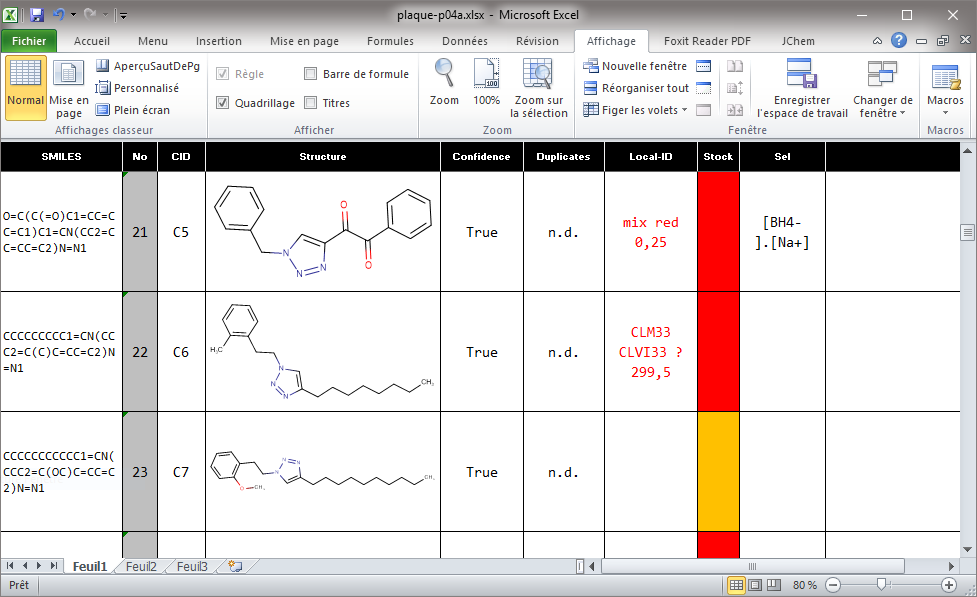
Enfin, il est possible de faire disparaitre ces A, B, C … qui ne sont pas utiles si vous ne les utilisez pas. Il faut aller dans l’onglet ‘Affichage‘ et décocher ‘Titres‘ et ‘Barre de formule‘. Les titres correspondent aux numéros de lignes sur l’axe vertical et aux titres de colonnes (‘A’, ‘B’, ‘C’ …) sur l’axe vertical, comme le montre la figure suivante qui est à comparer avec la figure de la section suivante ou les titres apparaissent.
 |
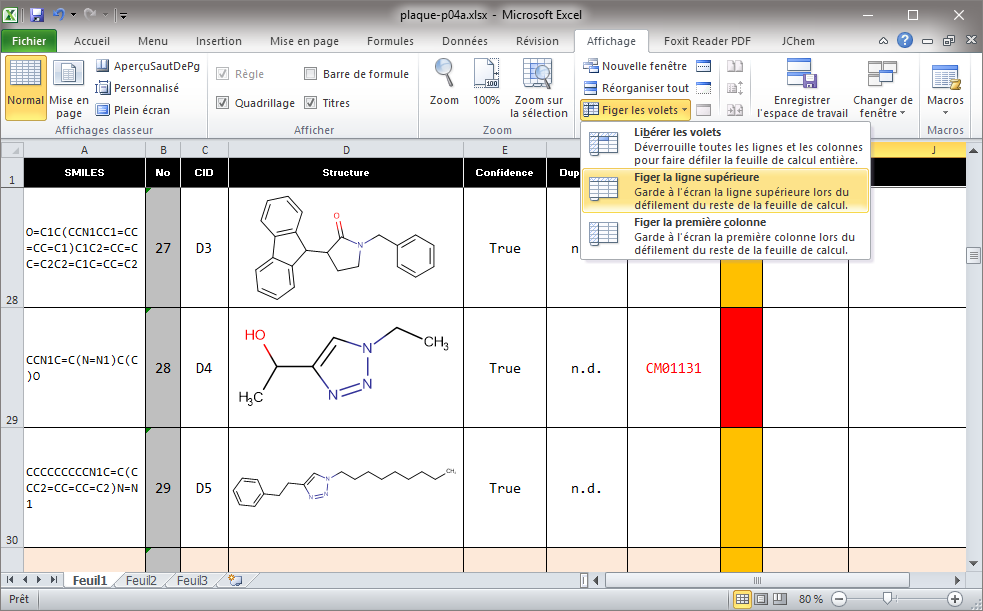
4. Figer la première ligne
Absolument indispensable ! De cette manière les titres qui sont contenus dans la première ligne sont bloquées quel que soit le défilement dans le fichier comme le montre l’image suivante ou la ligne 1 (fond noir) reste présente malgré la position dans le fichier qui se trouve au niveau de la ligne 28 (axe vertical à gauche). Il faut aller dans l’onglet ‘Affichage‘ puis ‘Figer les volets‘ et choisir l’option adaptée (‘Figer la ligne supérieure‘).
 |
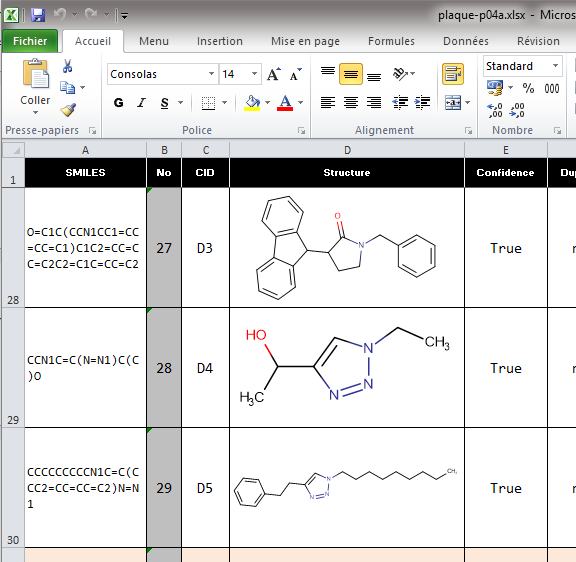
5. Renvoi automatique à la ligne (wrap)
Le texte apparaitra sur plusieurs lignes dans la cellule, de cette manière il ne sera pas masqué par la cellule adjacente de la colonne suivante. Option indispensable pour lire les chaines SMILES dans une table Excel. Dans l’onglet ‘Accueil‘ il faut sélectionner l’icône correspondante à droite du groupe ‘Alignement‘.
 |
6. Saut de ligne explicite dans une cellule
Il suffit de taper la combinaison de touches ‘Alt-Entrée‘ pour générer le retour de ligne. Dans les images de tables de cet article on note la présence de retours à la ligne dans les colonnes Confidence et Local-ID.
7. Choix multiples dans les cellules
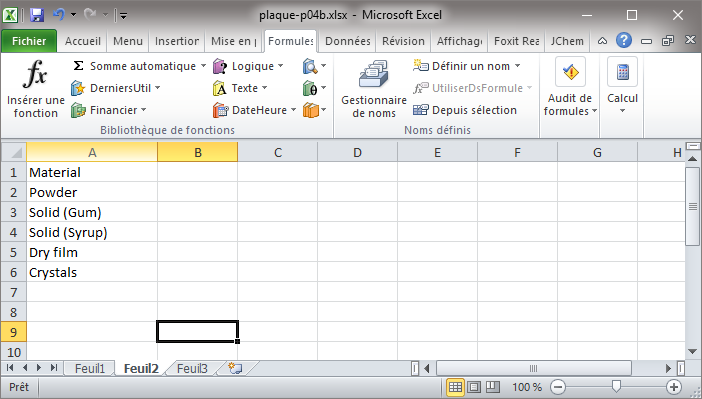
Application: figer la valeur d’une cellule sur des choix prédéfinis, par exemple Powder, Solid (gum), Solid (Syrup), Dry film, Crystals … pour l’état visuel des produits chimiques dans le tube.
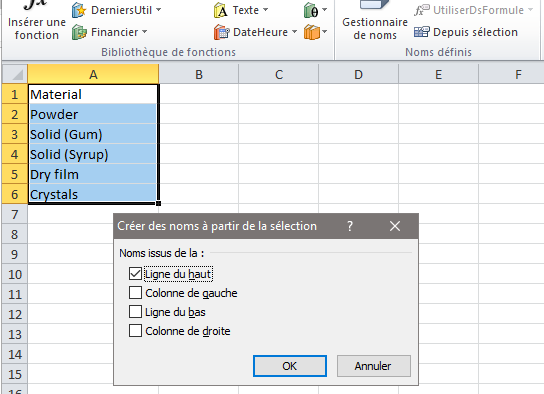
En premier lieu il faut créer une source de données que nous allons appeler Material. Dans une autre feuille (que la table de molécules) nous allons générer une liste avec la première ligne pour le nom de la liste (Material) et les autres pour les données (Powder …) qui apparaitront dans la liste déroulante (image de gauche). Puis nous saisissons les données, nous sélectionnons l’ensemble des cellules, puis dans l’onglet ‘Formules‘, nous validons en utilisant ‘Depuis sélection‘. Nous allons définir le nom de la liste en cochant ‘Ligne du haut‘ (images de droite).
 |
 |
| Création de la liste | Définition du nom de la liste |
Maintenant il s’agit de valider la liste et les données. Nous allons dans l’onglet ‘Données‘, et ‘validation des données‘, puis on paramètre: ‘Liste et options et la source‘ qui s’affiche automatiquement :
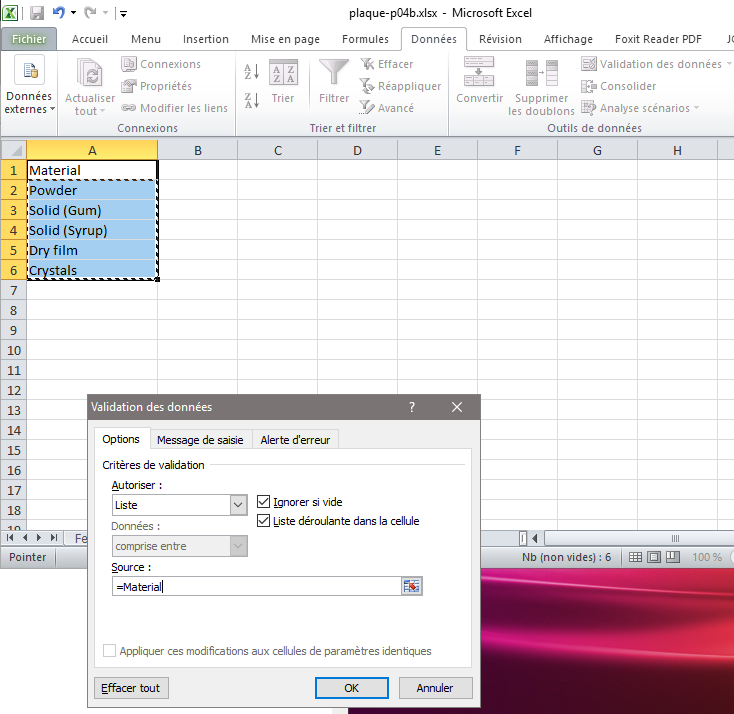 |
A ce niveau c’est fini pour les données, il reste à affecter cette source de données aux valeurs de la colonne qui va correspondre aux données à choix multiples et à l’implémenter sous la forme d’un menu déroulant, ce qui se fait en deux étapes.
La première concerne l’affectation à la colonne cible, pour cela, nous sélectionnons colonne puis l’onglet ‘Données‘ => ‘Validation des données‘ (image de gauche). La seconde consiste à rendre les données Material accessibles sous la forme d’une liste déroulante, nous ajoutons la chaine =Material (le = est collé à Material) dans l’item ‘Source‘ (image de droite).
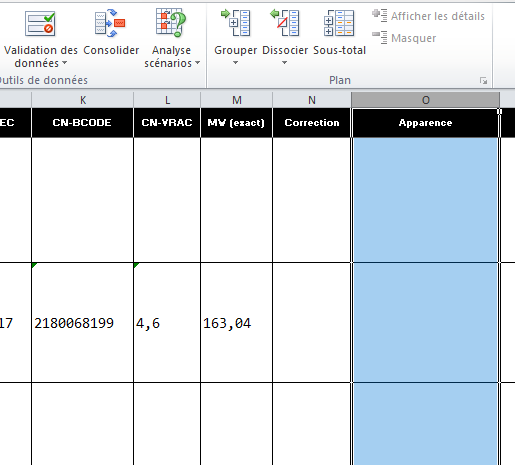 |
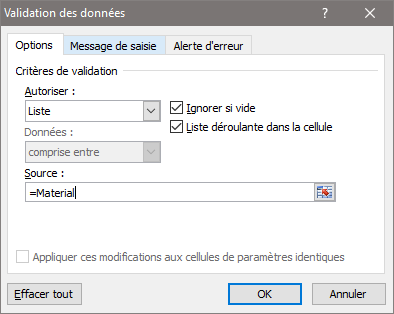 |
| Sélection de la colonne cible | Création de la liste déroulante |
Le menu déroulant devient alors accessible lorsque la colonne est sélectionnée :
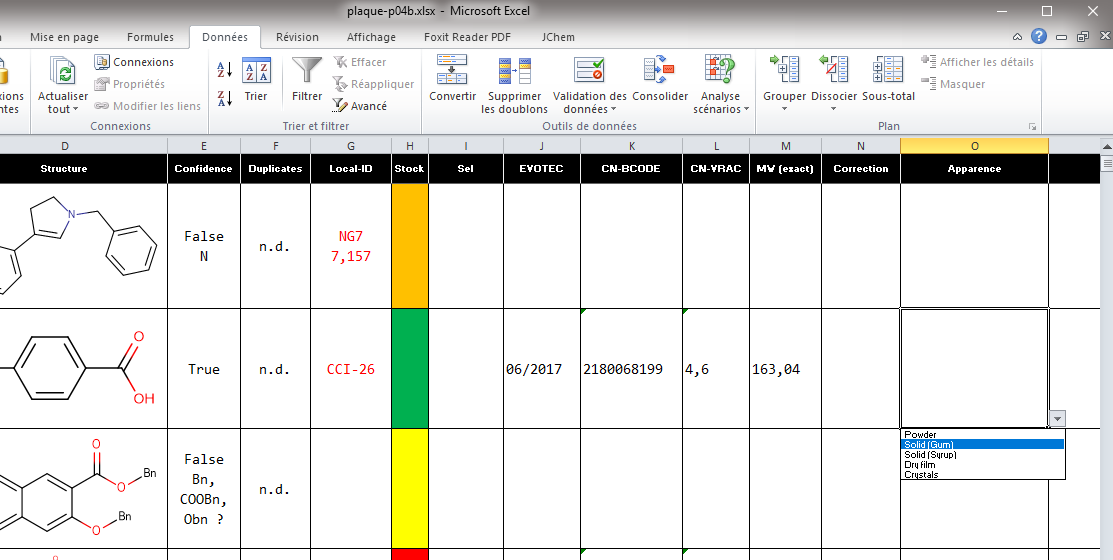 |
Il est possible d’ajouter ou de modifier les valeurs si la plage de la liste est la colonne (sélection A-A en utilisant l’onglet ‘Formules‘ puis le ‘gestionnaire de noms‘, ‘Modification‘, comme le montre l’image suivante :
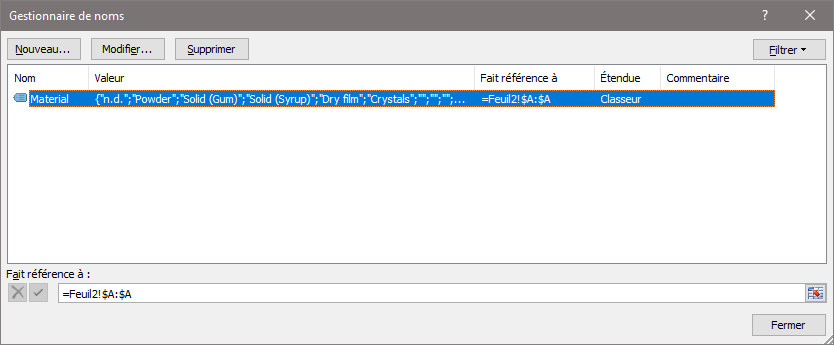 |
Par exemple dans ce cas, la liste s’appelle toujours Material mais la première valeur a été remplacée par n.d. (non défini/not defined). Il est toujours utile d’installer d’office ce type de valeur dans une cellule, qu’il s’agisse de la phase de saisie/collecte ou d’exploitation (export vers un système de données).
Il reste à régler la taille de la liste déroulante, mais l’impact est limité, car les cellules correspondent aussi à du texte, donc le copier/collé (pour peu qu’il correspond à une des valeurs de la liste) est valable. Donc on remplit très vite des cellules avec une valeur par défaut adéquate. Il ne reste qu’à modifier les valeurs qui sont différentes, manuellement avec la liste.
8. Conclusion
Nous avons donc la possibilité de rendre des tables impeccables aux utilisateurs finaux ou aux clients suite à une collecte de molécules. Tables que nous remplissons ou que nous donnons prêtes à remplir (des champs peuvent être pré positionnés aussi). Notez qu’il est bien plus pratique de travailler en local sur son tableur que de remplir les champs d’une base de données ou parfois l’utilisabilité n’est pas au niveau. Faites en l’expérience est vous verrez que le taux d’erreurs décroit significativement, sachant que la limite raisonnable me semble être de 40 molécules/heure, pour une collection diverse, et pour un taux de moins de 5% d’erreur après vérification par le chimiste concerné (je ne compte pas les corrections interactives en cours de saisie).
Liens et lectures