Il est possible de sauver le contenu d’un index filtré dans un fichier CSVM. Il s’agit d’une table (comme un fichier CSV ou Pandas) mais augmentée de métadonnées via différents mécanismes dans la table, pouvant inclure des annotations (éventuellement conservées) hors table, des valeurs alternatives pour une cellule, des blocs binaires, un petit niveau de récursivité (table incluse dans une cellule).
Cette note traite uniquement de l’aspect données: exporter un index. Mais nous pourrions tout à fait encoder une recherche dans un fichier CSVM, de manière à la sauvegarder d’une manière externe à un programme. Il suffirait de définir les clés (par exemple des identifiants de fonctions: filtres, outils de recherche …) puis d’aligner les arguments des fonctions dans les colonnes du CSVM, l’ordre des lignes définissant la séquence d’instructions.
1. Ajouter de l’information à un index
Mais tout d’abord je commence par la fonction index_addinfo qui permet d’ajouter des colonnes à un index au format simple ou dirmatrix. Son utilisation est très simple :
def index_addinfo(index, what, blank='-') |
Dans le cadre de fonctions liées aux index, l’information (la colonne) que l’on peut ajouter à l’index est définie par l’argument what, qui peut prendre comme valeur TYPE|DATE|MODE|TIME. Ces valeurs sont issues d’un appel à une fonction file_get_file_allinfo (basée sur la fonction os.stat de Python) du module buildez.file.py et qui renvoie une structure de données constituée de plusieurs éléments.
| Fonction | Données |
file_get_file_info(f) |
renvoie (name, fname, fext, rname, fpath) |
file_get_file_allinfo(f) |
renvoie [type, sdate.lower(), mode, stime,ino, dev, nlink, uid, gid, size, atime, mtime, ctime] |
La fonction index_addinfo utilise un conditionneur str_matrix_str_cond1 qui permet d’étendre l’index (de dimensions nr, nc) avec une colonne supplémentaire (nc+1) remplie avec une chaine définie par blank (dans mon cas, en général '' ou '-') et qui s’applique (valeurs >0) après les colonnes et lignes existantes (si on augmentait la valeur de nr).
index = str_matrix_str_cond1(nr,nc+1,blank,1,1,index) |
Si nous utilisons une des deux fonctions (conditionneur ou index_addinfo) nous pouvons ajouter ce que nous voulons comme information à un index, de manière à l’enrichir.
2. Export au format CSVM
Si l’on veut sauver un index, enrichi (après les colonnes réservées aux chemins et éléments terminaux) ou pas, il est possible d’utiliser les fonctions index_feed_csvm et index_makecsvm. Cette dernière fonction crée un objet de type csvm_ptr, puis utilise index_feed_csvm pour le remplir avec les valeurs de l’index.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
def index_makecsvm(index, blank='-', format='simple', root=''): """ This sub uses an index of files to feed and return a new CSVM structure using index_feedcsvm subroutine. The CSVM embbeds two columns labelled DIR and FILE for directory tree and files respectively. Updated for 'list|dirmatrix' formats. index_makecsvm(index, blank='-', format='simple', root='') index:matrix = file/dir index string matrix. blank:string = char used for CSVM blank data ('-' or '' as usual). :self:csvm_ptr = returned CSVM structure. *** 1.00/270925/Fred """ self = csvm_ptr() if (self == None): return None self = index_feedcsvm(self, index, blank, format=format, root=root) return self |
Il est possible après de sauver cette structure de données dans un fichier avec les fonctions du module csvm.py ou de l’exporter à d’autres formats (CSV, XML) via d’autres modules (csvm4csv.py, csvm4xml.py) du paquetage buildez.parsers.
3. Exemple d’exécution
Prenons le cas d’un index généré à partir de C:\Python3\envs\prod\Lib\site-packages\buildez avec un filtrage et un enrichissement : ajout de dates sur les items de l’index, avec une commande du type index = index_addinfo(index, 'DATE'). Pour un index au format dirmatrix, nous aurons une sortie du type suivant, portant sur 342 items :
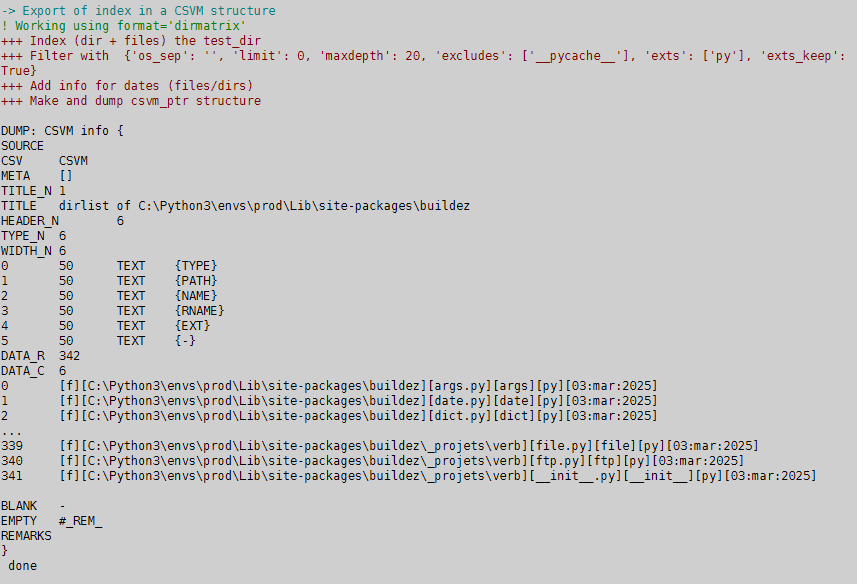 |
Les colonnes sont nommées et typées dans les descripteurs CSVM définis par #HEADER et #TYPE. La colonne ajoutée n’est pas nommée, pour le faire il faudrait utiliser directement l’objet csvm_ptr, par exemple: self.HEADER[5] = 'DATE', ce qui est très facile à faire au niveau applicatif. On note que les fonctions index_feed_csvm et index_makecsvm utilisent la racine de l’arbre en tant qu’argument, qui n’est pas nécessaire pour traiter l’index, mais qui se retrouve en tant que métadonnée (descripteur #TITLE) dans le titre de la table. Nous aurions pu ajouter d’autres informations dans le champ #META, avec différentes approches : liste d’éléments (simples ou clés-valeurs) avec séparateurs, texte JSON …
4. Conclusion
Nous disposons donc d’une surcouche qui permet d’aller vers un format pivot et de sauvegarder des recherche d’index pour utilisation ultérieure. Vu qu’un arbre sérialisé, c’est une matrice de chaines de caractères, ou chaque colonne correspond à un type de données, l’application à un fichier CSVM était évidente et immédiate.
Il n’y a pas de fonction d’import car il suffit de récupérer le bloc DATA du CSVM qui correspond au contenu de l’index (par exemple index = self.DATA, puis purger l’objet self). Cette approche est réservée au paradigme CSVM, soit des ilots de données (100 colonnes:10000 lignes en limite, typiquement un ratio 10:1000 que l’on va retrouver dans une cinétique ou un spectroscopie).
Il est également possible de purger cette table vis à vis des colonnes inutiles. Soit en direct, en utilisant le module strmatrix (par exemple str_matrix_delcols), soit en amont (sur l’objet csvm_ptr) en utilisant les modules csvm (par exemple csvm_ptr_delcol) ou csvmutils (par exemple csvm_ptr_cols_remove).
Liens et lectures
- Technical Report: CSVM Ecosystem [ https://arxiv.org/abs/1209.2946 ].