Nirsoft utilities est une source d’outils freeware dédiés à l’administration système sous Windows, mais on y trouve aussi une liseuse CSV très intéressante : CSVFileView. Cet utilitaire est dédié à la lecture de fichiers CSV délimités par des tabulations, il est léger, rapide et capable de lire, en natif, des fichiers CSVM. Nous allons ici explorer les fonctionnalités de cette liseuse dans le contexte CSVM.
CSVFileView is a simple CSV file viewer/converter utility that allows you to easily view the content of CSV or tab-delimited file created by NirSoft utilities or by any other software, in a simple table viewer. You can sort the lines according to one of the fields, remove unwanted fields and change their order, and then save the result back into CSV file, tab-delimited file, XML file, or HTML report. CSVFileView v2.65 – Copyright (c) 2011 – 2025 Nir Sofer [ https://www.nirsoft.net ].
Publication initiale : buidez.net (2012), version refondue et mise à jour en 2024-2025.
1. Le fichier CSVM test
Pour tester la liseuse, nous allons utiliser un fichier CSVM qui correspond à une collection de molécules (au format SMILES : colonne ‘Structure‘ ). Cette collection est annotée avec des commentaires (débutant par #) faisant référence à des blocs de lignes de données. Les ... pour indiquer que certaines lignes du fichier ne sont pas affichées pour alléger la présentation :
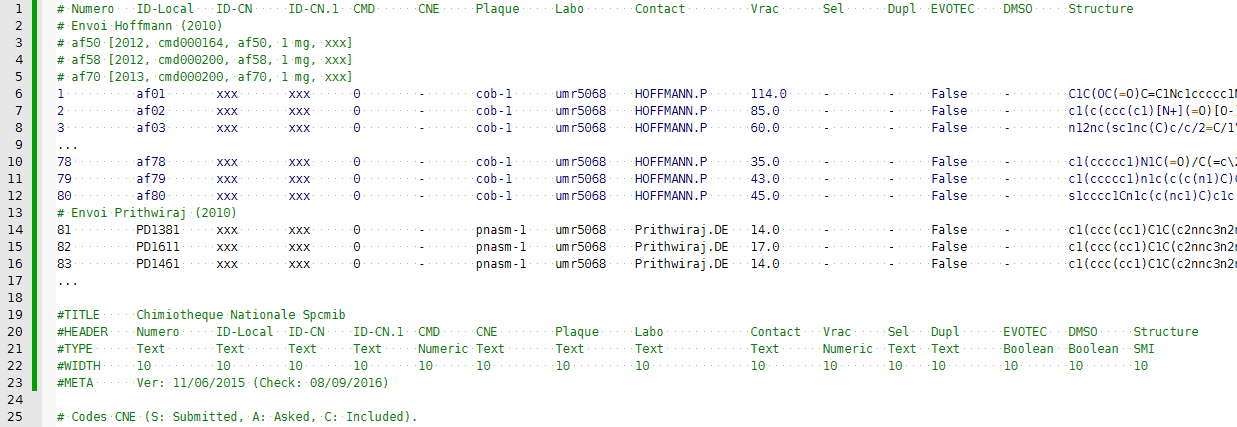 |
Pour bien comprendre les données, nous avons un fichier avec 15 colonnes (cf. lignes 1:# et 20:#HEADER) et n lignes organisées en blocs dans la section DATA. C’est une collection interne qui marque des molécules qui étaient envoyées à la Chimiothèque Nationale du CNRS (CN, aujourd’hui ChemBioFrance) et qui pouvaient être utilisées par d’autres partenaires (par exemple des Biologistes) pour réaliser des criblages, afin de tester si ces molécules pouvaient avoir une activité. Nous trouvons donc des quantités, des identifiants dans différentes bases, des structures au format SMILES (la colonne ‘Structure‘ est tronquée).
Le premier bloc, en bleu, est annoté 4 fois, par des lignes qui commencent par des #. La première (ligne 2) correspond à un envoi à la CN et correspondant généralement à la production d’un chimiste, les 3 autres (3-5) à des personnes qui ont bénéficié de molécules de ce bloc pour leurs projets scientifiques. Le second bloc, en noir (lignes 13 -à 16), est annoté une seule fois, juste le chimiste correspondant à un autre envoi. On pourrait croire que ces deux annotations sont redondantes avec la colonne ‘Contact‘. Il n’en est rien, chaque envoi pouvant correspondre à la production de plusieurs chimistes, c’est une information qui est orthogonale.
2. Lecture du fichier CSVM
Le fichier est délimité par des tabulations ce qui correspond à l’option principale de la liseuse CSV, en ce qui concerne les caractères séparateurs. Deux option sont disponibles ‘Open CSV\Tab-Delimited File’ et ‘Advanced Open …’. Bien que la première option soit utilisable pour lire un fichier CSV délimité par des tabulations, il sera préférable d’utiliser la seconde pour lire le fichier CSVM exemple. La fenêtre suivante apparaît :
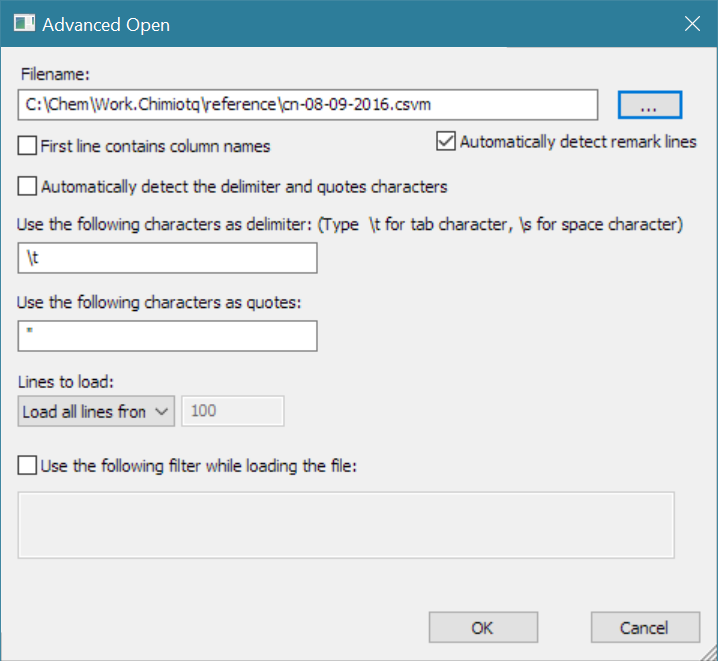 |
Nous utilisons le code '\t' pour signifier que le fichier est délimité par des tabulations, nous n’utilisons pas la première ligne pour nommer les colonnes (ce point sera revu plus loin) et nous interprétons les lignes de remarques (le caractère # est également reconnu par la liseuse en tant que signal pour une ligne de commentaires). Le résultat est le suivant :
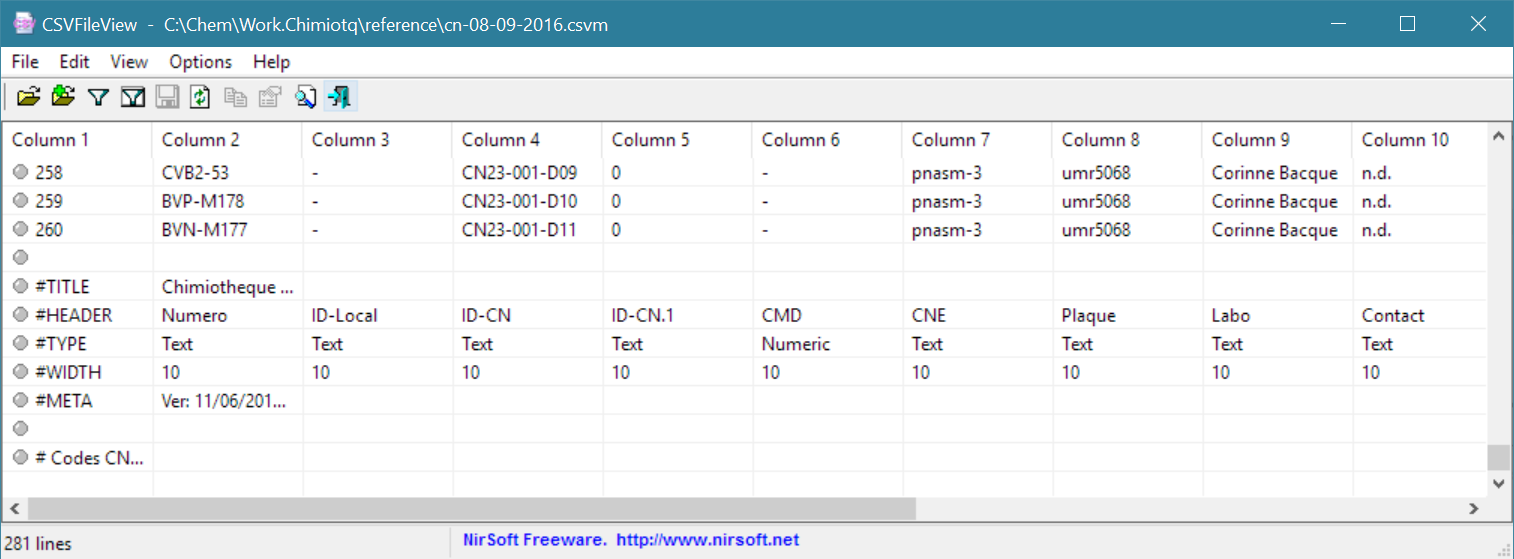 |
Nous constatons que les colonnes sont reconnues, les lignes vides sont prises en compte, le bloc de métadonnées n’est pas tronqué (il inclue une colonne en plus), les commentaires sont bien interprétés (dans le bloc de données et après le bloc de métadonnées). Un problème se pose pour les lignes de commentaires en début de fichier qui ne sont pas prises en compte.
Si le fichier est chargé sans chercher à interpréter les lignes de remarques, toutes les lignes marquées par un # apparaissent, y compris celles du début de fichier, ce qui correspond au résultat espéré.
3. Labellisation de colonnes
Si le fichier n’embarque pas une première ligne rule, le titre des colonnes ne s’affiche pas. Le nom des colonnes reste générique (Column 1, Column 2 …) ce qui est dommage pour la lecture. Si cette ligne est présente (comme dans le fichier exemple) le noms des colonnes va apparaître. Cette ligne est simple à générer, il suffit d’ajouter un commentaire en tête de fichier et de reproduire les colonnes de la ligne #HEADER, par exemple :
|
1 |
# Numero ID-Local ID-CN ID-CN.1 CMD CNE Plaque Labo Contact Vrac Sel Duplicates EVOTEC DMSO Structure |
La ligne rule sera neutre pour un parseur CSVM puisqu’il s’agit d’un commentaire. Par contre, étant délimitée par des tabulations elle sera interprétée comme première ligne par la liseuse CSVM. Il n’est pas nécessaire d’ajouter des caractères englobants comme des guillemets simples ou doubles généralement utilisés à cet effet dans la première ligne équivalente d’un fichier CSV. Nous obtenons donc :
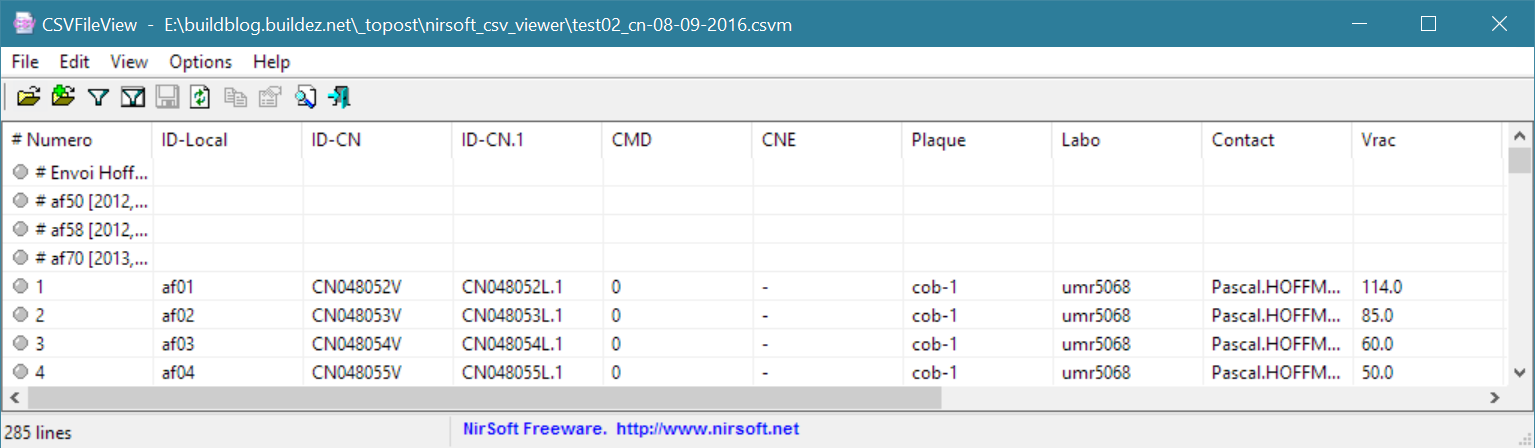 |
Cette première ligne (optionnelle) n’impacte pas sur le parseur, c’est juste une facilité qui est décrite dans la spécification. L’API python permet également de la générer par la programmation, via les fonctions csvm_ptr_make_csvm et csvm_ptr_csvm2file (option save_rule=True) du paquetage buildez.parsers.csvm.
Avec les options ‘First line contains column names’ et ‘Automatically detect remark lines’ activées, nous constatons donc que les colonnes sont correctement nommées, et que les remarques en en-tête du fichier apparaissent. Le survol à la souris d’une ligne de remarque (confinée à la première colonne) affiche la totalité de la ligne dans une info-bulle.
Snapshot d’une ligne
Si nous ‘double-cliquons’ sur une ligne de données, nous obtenons les champs (nom de colonnes et données) qui apparaissent de manière très lisible dans une fenêtre Properties. Ce qui est très utile quand les données correspondent à des chaines de caractères longues. Les champs peuvent également être copiés et collés dans une autre application, par exemple la chaîne SMILES (colonne ‘Structure‘) pour afficher la formule développée d’une af03 via ChemAxon MarvinView :
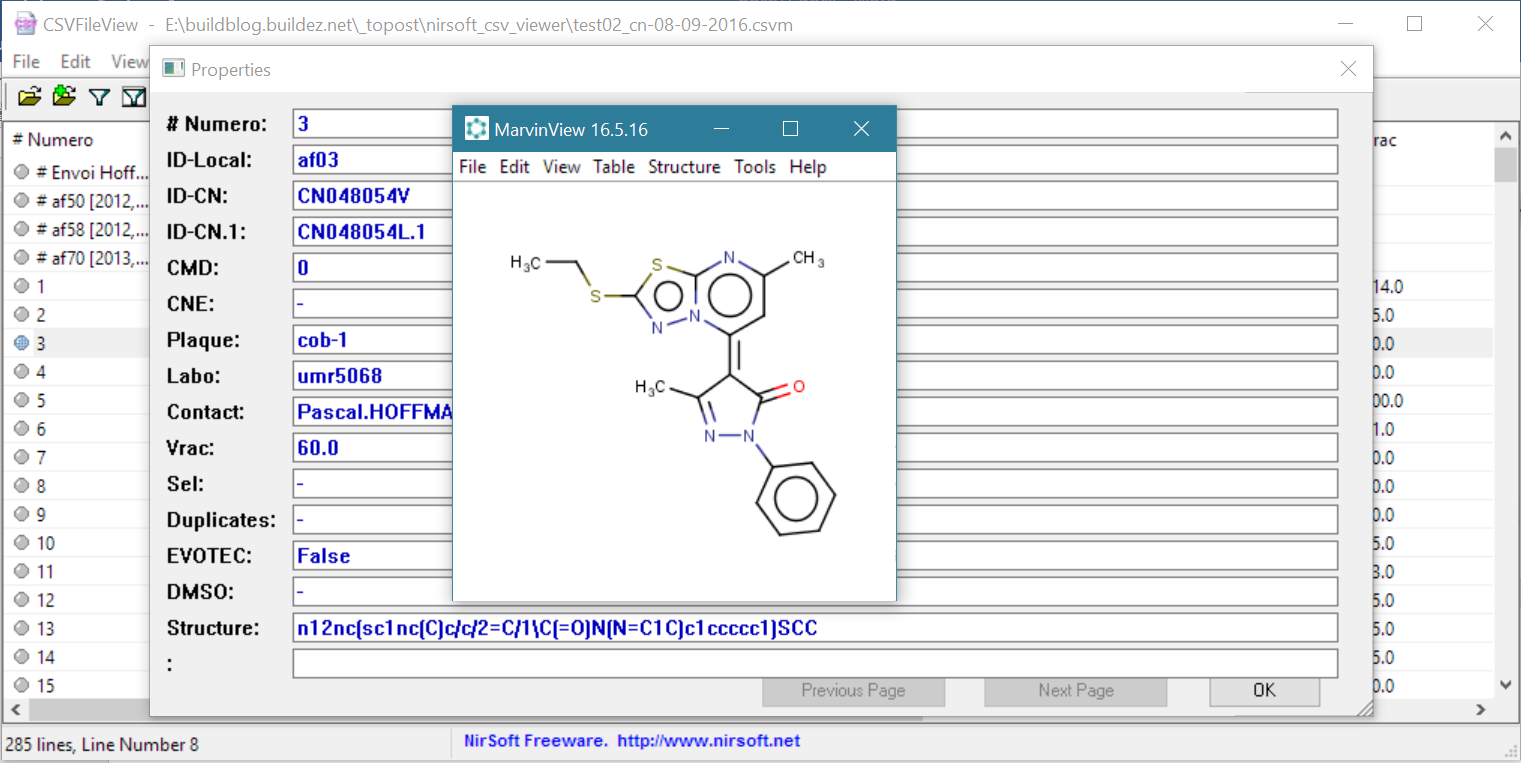 |
4. Exportation de données
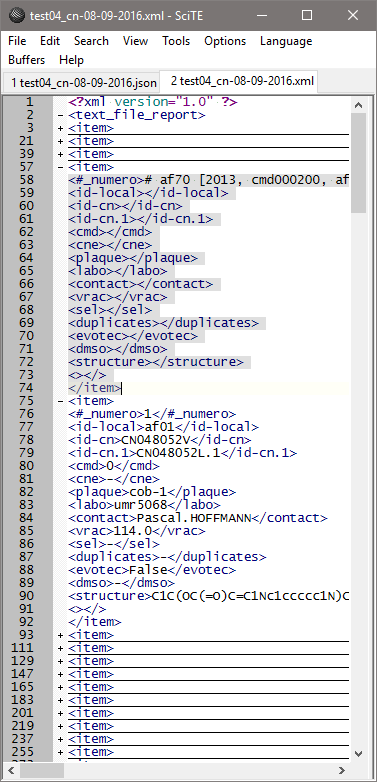
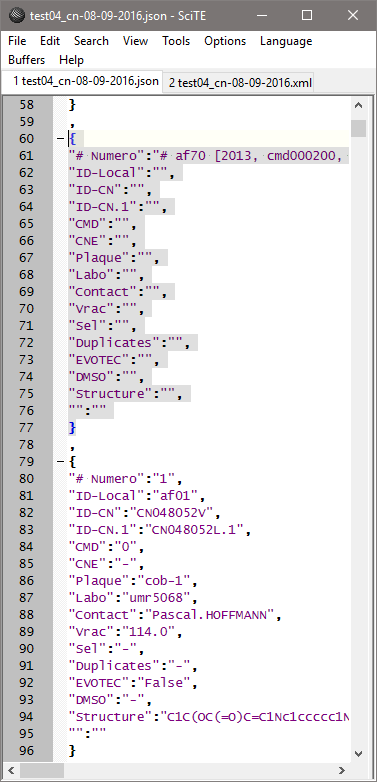
Si des cellules sont sélectionnées (par exemple toutes les cellules) il est possible avec le menu ‘File > Save Selected Items’ de sauver le contenu de la table à différents formats: {TAB, comma, custom} delimited text file, HTML (horizontal, vertical), XML, Json. Lorsque nous comparons les sorties XML et Json (pour la dernière ligne de commentaire en début de fichier et la première ligne du bloc de données) nous obtenons:
 |
 |
| XML | Json |
Nous constatons que le champ #_Numero (en fait la chaîne ‘# Numero‘) embarque la valeur du commentaire, incluant le marqueur #, puis les autres champs de données sont bien interprétés, mais vides, ce qui est logique. La ligne de données est également correctement interprétée, on note dans les deux cas une ligne sans champ nommé ("":"" ou <></>) qui pourra poser des problèmes aux parseurs XML/Json. Ces lignes vides résultent de la colonne qui a été ajoutée à toute la table. En effet, la liseuse interprète aussi le bloc de métadonnées CSVM qui comporte une colonne de plus, par définition. Ce qui explique aussi que le bloc de métadonnées CSVM n’est pas ‘maltraité’ dans les fichiers Json et CSVM.
5. Autres fonctionnalités
Parmi les fonctionnalités, nous trouvons un tri de cellules, qui n’est pas forcément utile pour la lecture de CSVM et qui va être perturbé par le bloc de métadonnées, ainsi qu’un support Unicode (Unicode/Ascii modes et UTF-8). Un filtre d’affichage programmable (multi-lignes combinables) basé sur une syntaxe similaire à la clause SQL WHERE est également disponible. Des exemples (contextualisés) de programmation sont affichés dans la fenêtre du filtre :
'# Numero' = '# Envoi Hoffmann (2010)' AND ID-Local = 'af01'
ID-CN = 'CN048052V' OR ID-CN.1 != 'CN048052L.1'
'# Numero' CONTAINS '# E'
Bien sûr, l’interprétation du CSVM est à la peine, mais on modifiera rapidement les lignes proposées en remplaçant le texte intégral par une chaine appropriée. Par exemple '# Numero' CONTAINS '# E' pourra être utilisé en '# Numero' CONTAINS '10' pour afficher toutes les lignes dont la colonne # Numero inclue la chaine ’10’ ce qui donnera ‘# Envoi Hoffmann (2010), ’10’, ‘100’, ‘101’, … ‘110’ … ‘210’. Le filtre '# Numero' LIKE '10' donnera pour sa part juste la ligne ’10’.
6. Conclusion
Nous avons donc une liseuse très efficace, multilingue (incluant FR). Il ne lui manque que d’accepter le coller ou la modification d’une cellule dans la fenêtre principale ou dans la sous fenêtre qui réunit colonnes/contenu pour une ligne donnée. Si c’était le cas nous aurions un éditeur CSVM (sans ajout/suppression de ligne toutefois) déjà très intéressant et léger, alternative à un tableur. A noter que CSVFileView ne peut pas prendre en compte les très grands fichiers mais cet outil restera très utile pour des ilots de données..
Liens et lectures
- Nirsoft freeware utilities [ https://www.nirsoft.net/ ].
- CSVFileView v2.65 – CSV / Tab-delimited file viewer and converter for Windows [ https://www.nirsoft.net/utils/csv_file_view.html ].
- ChemBioFrance [ https://chembiofrance.cn.cnrs.fr/ ].
- 15 NirSoft Utilities Every Windows User Should Have [ https://www.maketecheasier.com/nirsoft-utilities-for-windows-users/ ].
- Eric Fichot, traductions Nirsoft [ http://e.fichot.free.fr/?p=trad-nirsoft ].
- Sysinternals Suite (Mark Russinovich) [ https://learn.microsoft.com/fr-fr/sysinternals/ ].
- Control Sysinternals Suite & NirSoft Utilities with a Single Interface [ https://www.howtogeek.com/17683/control-sysinternals-suite-nirsoft-utilities-with-a-single-interface/ ].