2. Commentaires clés – valeurs
Prenons comme exemple un fichier CSVM issu d’un calcul d’analyse structurale, il s’agit d’évaluer la fluctuation dans l’espace d’un motif protéique (lignes: résidus 190 à 203) pour plusieurs structures PDB (colonnes) :
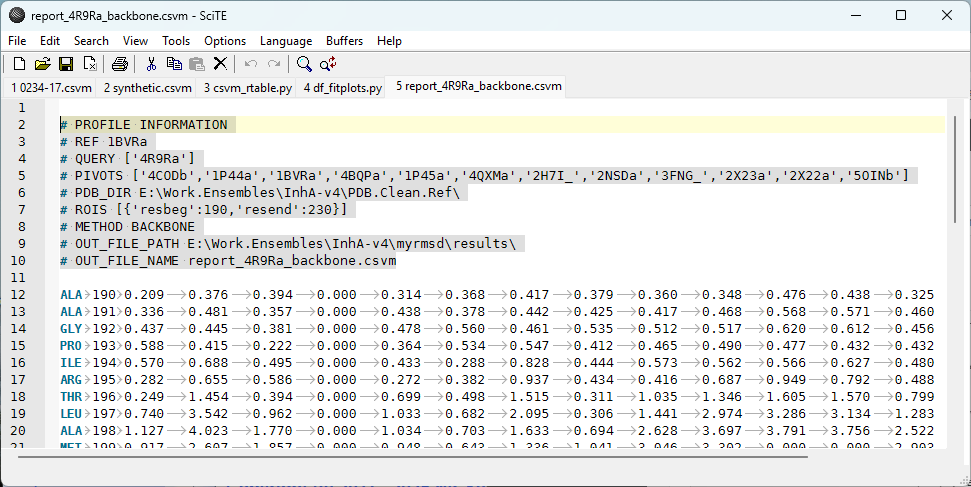 |
Nous constatons la présence (grisé) de lignes identifiées par des # avant le bloc de données (première ligne ALA 190). Le bloc est organisé en clés – valeurs délimitées par des espaces. Par exemple la chaîne ‘METHOD BACKBONE‘ sera interprétée comme {'METHOD':'BACKBONE'} sous la forme d’un dictionnaire Python. Pour prendre en compte ce bloc, la structure RTABLE de l’objet csvm_ptr va encore être utilisée, mais cette fois elle sera interprétée. Nous utilisons une fonction csvm_ptr_rtable2kvdict du module parsers.csvm_meta qui va lire ce bloc et le transformer en dictionnaire.
Mais que se passe t’il si nous avons plusieurs blocs ? En particulier avec les mêmes clés, mais avec des valeurs différentes, par exemple :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# PROFILE 1 # REF 1BVRa # QUERY ['<span style="color: #0000ff;">4R9Ra</span>'] # PIVOTS ['4CODb','1P44a','1BVRa','4BQPa','1P45a','4QXMa','2H7I_','2NSDa','3FNG_','2X23a','2X22a','5OINb'] # PDB_DIR E:\Work.Ensembles\InhA-v4\PDB.Clean.Ref\ # ROIS [{'resbeg':190,'resend':230}] # METHOD <span style="color: #0000ff;">BACKBONE</span> # OUT_FILE_PATH E:\Work.Ensembles\InhA-v4\myrmsd\results\ # OUT_FILE_NAME report_4R9Ra_backbone.csvm # END PROFILE # PROFILE 2 # REF 1BVRa # QUERY ['<span style="color: #ff0000;">4R9Sa</span>'] # PIVOTS ['4CODb','1P44a','1BVRa','4BQPa','1P45a','4QXMa','2H7I_','2NSDa','3FNG_','2X23a','2X22a','5OINb'] # PDB_DIR E:\Work.Ensembles\InhA-v4\PDB.Clean.Ref\ # ROIS [{'resbeg':190,'resend':230}] # METHOD <span style="color: #ff0000;">MAIN-CHAIN</span> # OUT_FILE_PATH E:\Work.Ensembles\InhA-v4\myrmsd\results\ # OUT_FILE_NAME report_4R9Sa_backbone.csvm # END PROFILE |
Les clés sont similaires, mais certaines valeurs sont différentes, par exemple pour la méthode de calcul (BACKBONE ou MAIN-CHAIN), pour la structure QUERY (4R9Ra ou 4R9Ra) … Dans ce cas (général) la fonction csvm_ptr_rtable2kvdic va fonctionner avec deux modes différents.
En mode val_list
Dans ce cas, nous lisons le fichier CSVM comme d’habitude, avec l’option save_rems=True, puis nous appliquons csvm_ptr_rtable2kvdict qui va nous renvoyer le dictionnaire kvdict :
|
1 2 3 4 5 6 7 |
c = csvm_ptr() c = csvm_ptr_read_extended_csvm(c, tfile, fsep="\t", save_rems=True, debug=0) blank = '-' (c, kvdict) = csvm_ptr_rtable2kvdict(c, meta_keys=['PROFILE'], mode='val_list', blank=blank, verb=1) if (len(kvdict) > 0): print("kvdict found:\n") pprint.pprint(kvdict) |
Dans ce cas (le niveau de verbosité positionné sur verb=1 pour avoir un rendu de l’analyse) pour une clé donnée, les valeurs correspondantes dans chaque bloc vont s’ajouter dans une liste. Nous aurons {'METHOD': ['BACKBONE', 'MAIN_CHAIN'], ... } pour le premier item du dictionnaire pdict :
 |
En mode key_name
Si nous fonctionnons avec ce mode, par exemple avec l’appel suivant :
|
1 |
(c, kvdict) = csvm_ptr_rtable2kvdict(c, meta_keys=['PROFILE'], mode='key_name', blank=blank, verb=1) |
Nous aurons chaque clé différentiée avec un numéro d’index dans le dictionnaire, soit {'METHOD': 'BACKBONE', 'METHOD02': 'MAIN-CHAIN', ...} pour comparer avec le cas précédent, ce qui nous donne :
 |
Nous avons donc la possibilité de ‘surcharger’ le fichier CSVM avec des annotations interprétables ayant les caractéristiques suivantes :
- De type clé – valeur.
- Qui ne correspondent ni à des données, ni à des métadonnées (au sens CSVM).
- Que l’on peut potentiellement agréger dans un dictionnaire.
- Que l’on peut associer à un ilot de données.
C’est typiquement le cas de paramètres expérimentaux. Et nous pouvons le faire sans définir des métadonnées supplémentaires, ou passer du temps à le faire, pour abandonner cette ‘normalisation’ peut être très rapidement.