Projet CSVM
Le format CSVM, dérivé du CSV, développé à la fin des années 90s, permet de stocker des données tabulaires accompagnées […]
Le format CSVM, dérivé du CSV, développé à la fin des années 90s, permet de stocker des données tabulaires accompagnées […]
Miniconda est la version light (400 Mo) de Anaconda (3 Go). Miniconda est basé sur Python 2 et Miniconda3 est
Dans le domaine du drug-design au sens large, il nous reste Click2Drug opéré par l’Institut Suisse de Bioinformatique (Swiss Institute
En évitant de générer une nième page de ressources qui sera rapidement obsolète, cette liste regroupe des sources de données
Comment s’organise le travail entre modélisateurs et utilisateurs (ou clients) finaux avec Molegro ? Il y a plusieurs manières de
Nous continuons notre découverte des formats moléculaires utilisés au laboratoire avec InChI, qui correspond à International Chemical Identifier. Il s’agit
Il existe toute une série d’outils écrits en Python et destinés à lire des fichiers PDB, en mode filtre ou
Les premières versions de buildez.pdb étaient écrites en Perl et utilisaient un ancêtre non typé de la matrice pdbm: la
Un catalogue pour les outils à finalité recherche que l’on peut installer sur son ordinateur personnel, hors langages informatiques, outils
Nous utilisons à la fois un IDE connecté à Python avec sa console et un shell dans lequel nous pouvons
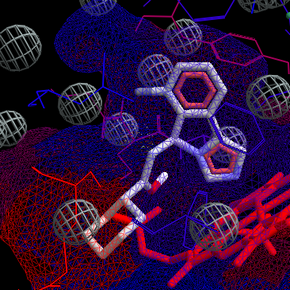
Molegro Molecular Viewer (MMV) est un programme qui permet la visualisation des résultats de docking réalisés avec Molegro. Cet outil
Le portage de buildez.pdb vers Python 3 a été terminé tardivement, entre 2023 et 2024, pour des raisons de dépendances
Le paquetage buildez.pdb regroupe toute une série de fonctions qui permettent une manipulation approfondie de fichiers PDB, de manière à

Ce guide porte sur les formats moléculaires utilisés pour manipuler des petites molécules, plutôt coté chimie. Donc des composés organiques

Une série d’articles destinés à faciliter la prise en main de Molegro qui est un outil d’arrimage moléculaire (docking). L’objectif
Savoir intégrer un alignement de séquence dans un processus structural n’est pas une option. Par exemple UCSF Chimera/Matchmaker utilise ce
Il y a toujours un moment ou nous avons besoin d’aligner des séquences protéiques, cela va de la modélisation par
Nous avons intérêt à savoir gérer une multitude de petites collections de molécules (ligands, inhibiteurs, substrats …) ce qui est

La Banque de données PDB (Protein Data Bank) est notre source principale d’obtention de coordonnées structurales (structures 3D) d’enzymes, de